




In unserem In unseremletzten Deep Dive zum maschinellen Lernen haben wir die verschiedenen Probleme erörtert, die bei der Textklassifizierung im Rahmen des maschinellen Lernens auftreten können, und wie man sie lösen kann. Heute möchten wir die verschiedenen Theorien auf einen Anwendungsfall anwenden. Wir werden untersuchen, wie Textklassifizierungsprobleme bei der E-Mail-Sichtung behandelt werden können.
Beginnen wir mit einem Vergleich zwischen einer E-Mail und einer Frage in einem Chatbot. Normalerweise ist eine Frage in einem Chatbot sehr kurz:
"Wie ist das Wetter morgen?"
Im Gegensatz dazu kann die Hauptintention in einer E-Mail ziemlich versteckt sein, z. B. wenn Sie eine E-Mail weiterleiten und in den Textkörper "fyi" schreiben. In diesem Fall scrollt der Empfänger in der E-Mail nach unten und findet zuerst die Kopfzeile der vorherigen E-Mail, im besten Fall gefolgt vom Textkörper, der irgendwo die Hauptinformation enthält. Dann folgt auf den Textkörper in der Regel eine lange Fußzeile. Handelt es sich um einen Strang von E-Mails, dann gibt es sogar mehrere Körper. Kurz gesagt, um zur Hauptaussage einer E-Mail zu gelangen, muss man sie möglicherweise gründlich analysieren. Beim maschinellen Lernen wird dies als Vorverarbeitung bezeichnet.
Vorverarbeitung
Die Vorverarbeitung von E-Mails sollte mindestens die folgenden Punkte berücksichtigen:
- Rechtschreibfehler
- Synonyme
- E-Mail-spezifische Muster
- Erkennung von benannten Entitäten
Um ein gutes Verhältnis zwischen Modellleistung und investierter Vorverarbeitungszeit zu erzielen, können Sie sich auf die Erkennung von E-Mail-spezifischen Mustern und benannten Entitäten beschränken.
"Ein äußerst hilfreiches Werkzeug sind reguläre Ausdrücke, kurz Regex."
Nehmen wir die Schweizer Sozialversicherungsnummer als Beispiel für eine benannte Entität. Diese Nummer ist immer 13 Ziffern lang und beginnt mit 756. Wenn Sie ein anständiges Modell zur Erkennung von benannten Entitäten mit genügend Daten trainieren, könnte es natürlich lernen, dass das Wort "756.1234.5678.90" eine Schweizer Sozialversicherungsnummer ist. Eine einfache Alternative zum Aufbau eines maschinellen Lernmodells für die Erkennung benannter Entitäten ist die Verwendung eines Musters, das als regulärer Ausdruck (Regex) bezeichnet wird. Mit Regex kann eine E-Mail erheblich reduziert werden, wie das Beispiel in den Abbildungen 4 und 5 zeigt.
Abbildung 4: Original-E-Mail
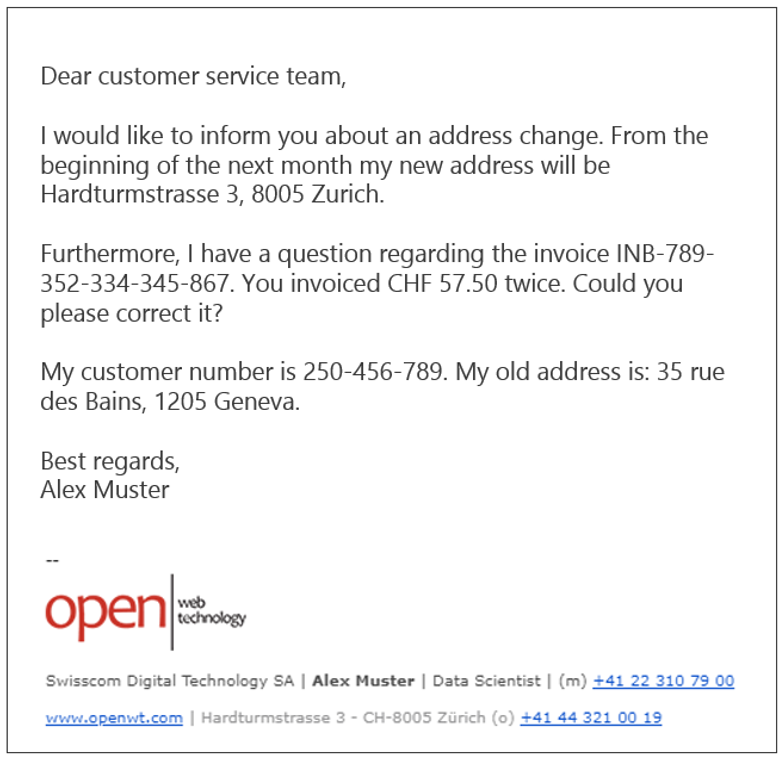
Abbildung 5: Vorverarbeitete E-Mail
Die Erkennung von Postadressen ist etwas schwieriger als die Verwendung von Regex. Alle anderen benannten Entitäten und Muster in Abbildung 4 können jedoch problemlos mit Regex-Ausdrücken behandelt werden.
Erstellen und Trainieren eines Modells
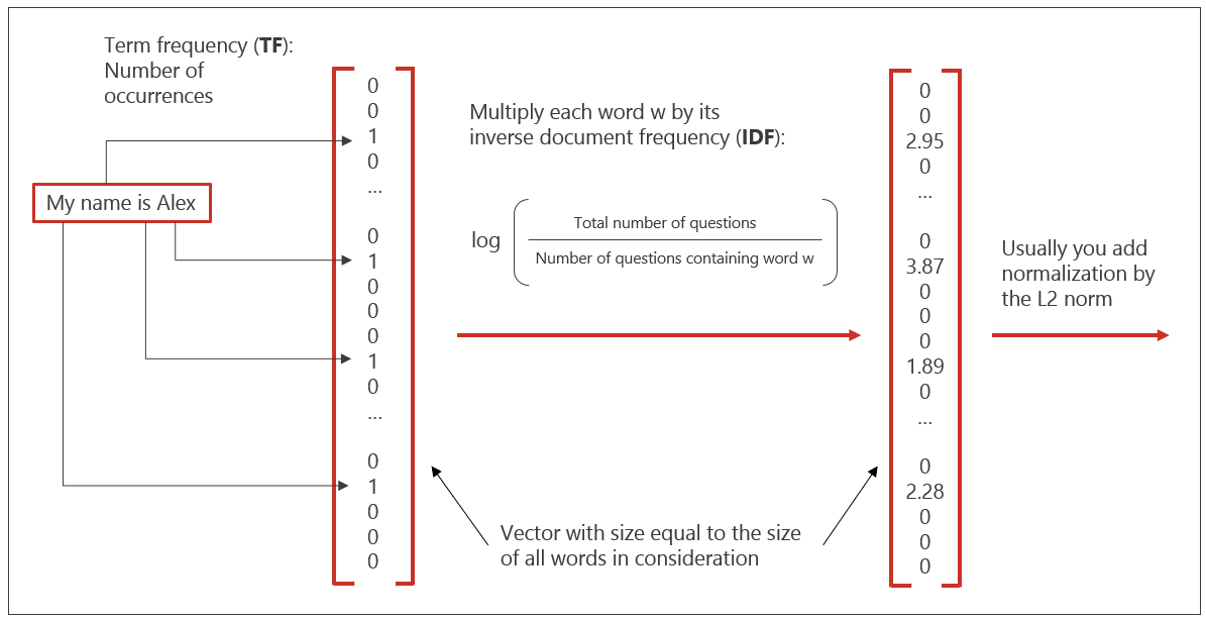
Sobald der Text vorverarbeitet ist, müssen Sie ein Modell auswählen, um den E-Mail-Klassifikator zu trainieren. Baumbasierte Methoden wie Random Forests und Gradient-Boosting-Entscheidungsbäume liefern in der Regel sehr gute Ergebnisse (in Python siehe zum Beispiel randomforest von sklearn, xgboost oder lightgbm). Um sie verwenden zu können, müssen wir den Eingabetext in numerische Vektoren umwandeln. Es gibt viele Methoden wie doc2vec, um eine solche Transformation durchzuführen, aber eine der einfachsten und leistungsfähigsten ist die so genannte Termfrequenz-Inverse-Dokumentenfrequenz-Methode TF-IDF (bei baumbasierten Methoden ist die Nützlichkeit des "IDF"-Teils allerdings fraglich). Siehe Abbildung 6 für eine kurze Erklärung der TF-IDF-Methode, die wir an einem Chatbot-Fragen-Korpus angewendet haben.
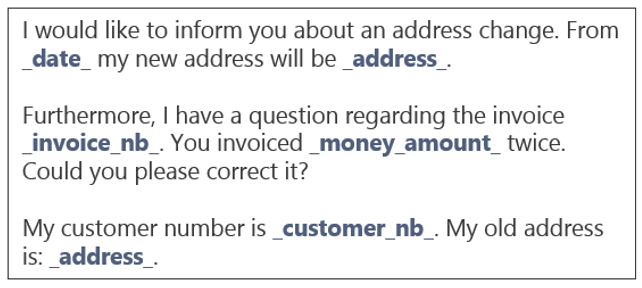
Abbildung 6: Wie man Text mit TF-IDF in einen Vektor umwandelt.
Nach diesem Schritt wird jede E-Mail in der Trainingsmenge als numerischer Vektor dargestellt. Zusammen mit den E-Mail-Beschriftungen, die die Kategorien darstellen, in die wir jede E-Mail einordnen wollen, können wir das Modell trainieren. Im Fall der E-Mail-Sichtung für einen Kundendienst könnten die Bezeichnungen "Adressänderung", "Anmeldeproblem", "Produktfrage", "Frage zur Rechnung", "Treuekarte" usw. lauten. In der vorherigen Abbildung 4 hätte die E-Mail zwei Bezeichnungen "Adressänderung" und "Frage zur Rechnung".
Nachdem Sie ein erstes Modell für die Textklassifizierung erstellt haben, können Sie das Endergebnis verbessern, indem Sie andere Textvorverarbeitungstechniken ausprobieren.
Auswertung des Modells und Vorhersage
Sobald Sie das Modell erstellt haben, müssen Sie es auswerten. Wenn Sie Verbesserungsmöglichkeiten sehen, gehen Sie zurück zu Schritt 1 über die Vorverarbeitung und beginnen Sie von vorne.
"Wie kann man ein Modell am besten bewerten?"
Die Antwort auf diese Frage hängt stark vom Kontext und von den Anforderungen des Anwendungsfalls ab. Die einfachste Bewertung ist die Genauigkeit des Modells. Sie ist am einfachsten zu erklären, z. B. für die Beteiligten in der Wirtschaft. Wenn die Kennzeichnungen jedoch nicht gleichmäßig verteilt sind, ist dies eine eher schlechte Wahl. Betrachten wir ein extremes Beispiel, nämlich Fälle von Betrugserkennung, bei denen wir davon ausgehen können, dass 1 von 1000 Proben ein Betrug ist. Wenn wir vorhersagen, dass nichts ein Betrug ist, dann haben wir eine Genauigkeit von 99,9, was in diesem Fall nichts bedeutet. Beispiele für andere Bewertungsmaßstäbe, die häufig verwendet werden, sind:
- Cohen-Kappa
- Log-Verlust oder Kreuzentropie
- F1-Punktzahl
- Fläche unter der ROC-Kurve (AUC)
- Präzision und Rückruf, Empfindlichkeit und Spezifität, insbesondere
Insbesondere für die E-Mail-Triage kann es sinnvoll sein, sich die Konfusionsmatrix des Modells anzusehen. In Abbildung 7 sehen Sie ein Beispiel für die Konfusionsmatrix für unseren unternehmensinternen Chatbot.
Abbildung 7: Konfusionsmatrix unseres firmeninternen Chatbots.
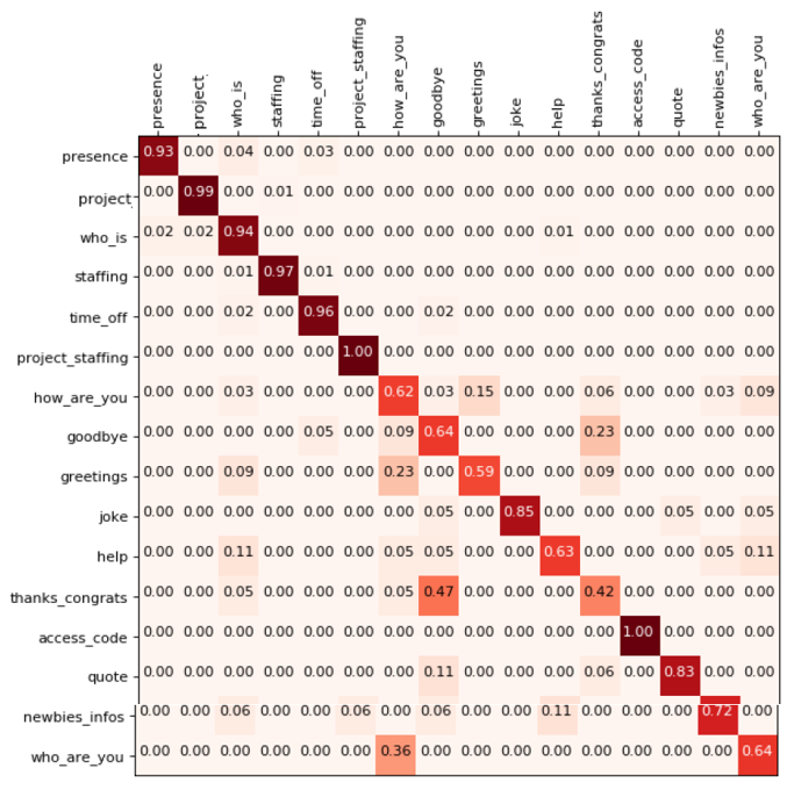
Wenn man sich diese Verwirrungsmatrix ansieht, kann man erkennen, dass es zum Beispiel einige Verwirrungen bei den Intentionen "Wie geht es Ihnen?", "Auf Wiedersehen" und "Grüße" gibt. Wenn man jedoch fragt, was die wichtigsten Anwendungsfälle für die Mitarbeiter des Unternehmens sind, sind es wahrscheinlich nicht diese Intentionen, die auf Unterhaltung abzielen, sondern eher Intentionen wie "Wer ist Alex", "Was ist meine Besetzung", "Wer ist anwesend/erreichbar". Auch wenn die Gesamtleistung des Modells mit einer der oben genannten Metriken vielleicht nicht so gut ist, kann das Modell für den tatsächlichen Geschäftsfall sehr gut optimiert sein. Natürlich können Sie die obigen Metriken auch gewichten, um den geschäftlichen Anforderungen gerecht zu werden. Die Visualisierung in der Konfusionsmatrix ist jedoch ein sehr intuitives Werkzeug, das jeder versteht.
In diesem Einblick haben wir die wichtigsten Schritte zur Erstellung eines maschinellen Textklassifizierungsmodells für den Anwendungsfall E-Mail-Sichtung durchlaufen: Textvorverarbeitung, Modellerstellung, Modelltraining und schließlich die Modellbewertung. Weitere Anwendungsfälle für künstliche Intelligenz finden Sie auf unserer speziellen Seite. Bleiben Sie dran für den nächsten Einblick in die Keras-Technologie!
können Sie mehr über den Anwendungsfall des maschinellen Lernens lesen: Keras für die Textklassifizierung


